結構化設計-概要設計
前言
結構化設計,可再區分為概要設計與細部設計兩個階段。概要設計的工作,主要是功能的模組化與資料庫的正規化,因此,概要設計可說是分析的邏輯概念與設計的實作技術之間的橋樑。
本文主要是說明概要設計裡,功能如何模組化、資料庫如何正規化,以及相關的表示方法與運用方式。
邱奕南,2009/9/28
良好模組的特性
模組(Module),是由一堆具有共同目的或特性的功能函數所組成。一個良好的模組,大抵必須考量以下的品質特性:
- 易讀性:模組的目的或特性容易被理解並認同為一個獨立的單元。
- 簡易性:有助於減少整個系統的複雜度。
- 測試性:可獨立系統之外進行個別測試。
- 再用性:容易再使用在其他系統中。
- 替換性:符合界面規格的模組皆可相互替換。
- 效能性:欲提升系統效能,只需調整個別模組,而不必調整整個系統。
- 安全性:模組裡的異常僅限於模組中,而不會影響到其他的模組。
- 維護性:任一需求變更時,只會影響個別的模組,而不會造成整個系統大幅變動。
注意這些品質特性並非全部皆能達成的。現今衡量模組的良好與否,多以內聚力和耦合力來評斷,而以高內聚力、低耦合力者為佳。
內聚力(Cohesion)
內聚力指的是模組內各功能函數之間的共同緊密程度,愈高愈好。以下按內聚力由高而低,介紹各種形態的內聚力:
- 功能內聚(Functional):模組內只包含一個用來完成一件特定工作的功能函數。
- 序列內聚(Sequential):模組內的功能函數,皆用來完成一件特定的工作,且必須依序執行,亦即前一個函數的輸出資料為下一個函數的輸入資料。
- 溝通內聚(Communicational):模組內的功能函數,皆具有相同的目的,且使用相同的輸入或輸出資料。大部份的公用函數庫皆屬於這個層次,例如浮點運算函數庫。
- 程序內聚(Procedural):模組內的功能函數為任務相關,各功能函數必須以一個特定的次序依序執行,方能完成一件工作。
- 時間內聚(Temporal):模組內的功能函數為任務相關,且必須在一定的時間範圍內執行,例如每日結束時的應執行程序。
- 邏輯內聚(Logical):模組內的功能函數為任務相關,但是否執行、以及其執行次序皆由外界自行選擇決定。
- 偶然內聚(Coincidental):模組內的功能函數彼此之間沒有任何有意義的關係。
一般而言,程序內聚以上的模組,皆被認為良好的模組,時間內聚以下的模組,皆被認為不佳的模組。以下為判斷模組內聚力的方法:
- 模組是否只包含一個用來完成一件特定工作的功能函數?是:功能內聚,否:問題2
- 模組的功能函數是以什麼做為連接?資料:問題3,流程:問題4,無:問題5
- 功能函數的執行順序是否重要?是:序列內聚,否:溝通內聚
- 功能函數的執行順序是否重要?是:程序內聚,否:時間內聚
- 功能函數之間是否有關連?是:邏輯內聚,否:偶然內聚
耦合力(Coupling)
耦合力指的是模組與模組之間的交互關聯程度,愈低愈好。以下按耦合力由低而高,介紹各種形態的耦合力:
- 資料耦合(Data):模組與模組之間係以簡單的資料形態做為輸出入參數進行溝通。注意要避免資料流浪現象(Tramp),亦即每個功能函數都有同一資料做為輸出入參數,不管它需不需要。這種情況的耦合力,其實相當於共用耦合。
- 戳記耦合(Stamp):模組與模組之間係以結構的形式封裝資料,做為輸出入參數進行溝通。注意結構裡的各資料必須具有相同之目的,避免無意義的包裹式結構(Bundling),亦即將各種無關的資料都統包在一個結構裡。這種情況的耦合力,也是相當於共用耦合。
- 控制耦合(Control):模組與模組之間具有可控制對方內部執行邏輯的輸入參數,例如控制旗標。注意控制用的資料,應避免混用情況(Hybrid),亦即不同的值域各代表完全不相干的目的或意義。這種情況的耦合力,已相當於內容耦合。
- 共用耦合(Common):模組與模組之間,具有可共同存取的資料,例如全域變數(Global Variable)、檔案、資料庫等。
- 內容耦合(Content):模組與模組之間,可直接存取對方內部的資料,或執行對方內部的程式。
一般而言,控制耦合以上的模組,皆被認為良好的模組,共用耦合以下的模組,皆被認為不佳的模組。
程式結構圖(Structure Chart)
程式結構圖,又稱模組結構圖,係以圖形來表示各模組之間的參用關係。以下便是一個基本例子:
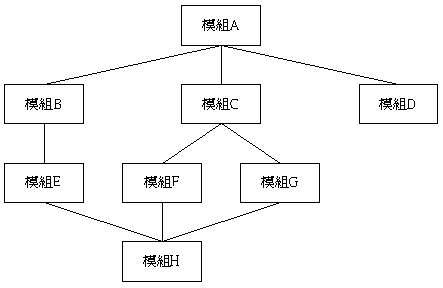
圖例中,模組A參用了模組B、C、D,模組H則由模組E、F、G所參用。
功能模組化
如何將資料詞典中的資料處理功能,依其特性,集結並切分成適當的模組,並形成容易維護的模組架構,其實並沒有想像中的容易。傳統的結構化設計,多從資料流程圖進行切分與合併,以產生出模組,但這樣的模組是否適當,其實很難說。故在轉換(Transform)的過程中,多會再提及一些建議的原則:
- 遵循由上到下(Top-Down)、由簡而繁的原則進行模組切分。
- 在程式結構圖中,上層應儘量利用高度的扇出(Fan-Out,該模組直接參用的模組數目),以將結構最小化,底層則應儘量致力於扇入(Fan-In,直接參用該模組的模組數目),以集結出共用的模組。
- 儘量維持模組的影響範圍在扇出模組的可控制範圍內。
- 評估程式結構圖中各模組的內聚力與耦合力,並適當地加以分裂(Explode)或合併(Implode)。
- 避免初始化或結束用的模組,並避免模組記錄上次呼叫後的結果或狀態。
- 儘量維持程式結構圖的簡易性與易讀性。
以下,作者嘗試以多年的經驗,提出一些模組化的切分定則供參考:
- 找出需要存取的外部資料,如資料庫或檔案等,將其存取的功能獨立成一到多個模組(視資料源或檔案特性而定)。
- 找出需要存取的系統資料,如系統設定等,將其存取的功能獨立成一到多個模組(視資料的特性而定)。
- 找出須與外部系統溝通的功能,如通訊、提供界面函數等,將之獨立成一到多個模組(視外部系統與功能特性而定)。
- 找出需要資料實體輸出的功能,如報表、匯出等,將之獨立成一到多個模組(視輸出的媒介與形式而定)。
- 找出需要人機界面溝通、顯示的功能,將之獨立成一到多個模組。
- 找出與硬體設備、作業系統、協同軟體相關的功能,將之獨立成一到多個模組。
- 找出與效率嚴重相關的功能,將之獨立成一到多個模組。
- 找出作法多種或易變的功能,例如與理論、公式相關者,將之獨立成一到多個模組。
- 其餘功能,按資料流程圖,由最上層開始進行垂直分割,並按前述原則進行模組化。
資料庫關聯圖
在尚未有資料庫之前,結構化分析設計皆採用資料結構圖(Data Structure Diagram,簡稱DSD)來定義檔案間的鍵值對應關係,現今則皆已改用資料庫關聯圖來表示資料表間的鍵值關係,其實這兩種圖可說是幾乎完全一樣的,所差別的只是對象(檔案/資料表)的不同而已。以下便是一個例子:
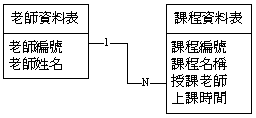
其中各資料表與所屬資料項的來源,便是系統分析所得的實體關係圖之實體與所屬屬性。注意在繪製資料庫關聯圖之前,應先進行正規化的動作。
資料庫正規化
資料庫正規化的目的,主要在於減少資料庫裡的資料冗餘,增進資料的一致性。正規化的型式,依次為第一正規化、第二正規化、第三正規化、第四正規化(又稱BC正規化)、第五正規化,後者皆包含前者。對於資料庫而言,一般只要求到第三正規化即可。
第一正規化:消除重複群。亦即資料表沒有重複出現的欄位,且每一筆記錄的每一欄位均只存放單一的資料值,並可由唯一的主鍵識別該記錄。
- 消除重複欄位:凡是具有相同意義的欄位,如經理1、經理2等,應合併成為一個重複資料的欄位,並按後述方式處理。
- 消除多重值:若某個欄位的一筆記錄裡有多個值時,應拆成多筆記錄分開存放。
- 找出主鍵:對每個資料表,均賦予一個主鍵欄位,或由多個欄位組成的複合主鍵。每一筆記錄的主鍵值均必須不同。
第二正規化:符合第一正規化,並具有相依性。亦即每一個非鍵欄位都完全相依於主鍵欄位,且只能由該主鍵值來識別取得。
- 畫出欄位資料相依圖,確認所有的欄位均相依於主鍵。
- 凡新增記錄會有無法決定的初始值、刪除記錄會造成需要的資料遺失、修改記錄內容會造成資料不一致者,大多屬非完全相依的欄位。
- 所有非完全相依的欄位,均應移到另一個新的資料表中。
第三正規化:符合第二正規化,並消除遞移相依。亦即每一個非鍵欄位彼此之間不可有相依關係。
- 畫出欄位資料相依圖,確認所有的非鍵欄位間沒有相依關係。
- 凡具有遞移相依的欄位,應將之分拆成至不同的資料表中。
- 由於第三正規化容易導致太多小型資料表,進而降低了資料庫的存取效能,故實務上多只針對異動頻繁的資料表進行第三正規化。
需求回溯表
- 正向回溯表:以功能為主,表列各功能所屬的模組。
- 反向回溯表:以模組為主,表列各模組所含的功能。
參考文獻
- 軟體工程實務專家作法,第四版,Roger S. Pressman原著,金子葳等人譯,儒林,1998
- The Practical Guide To Structured Systems Design, 2nd Edition, Meilir Page Jones, 1988
- 資料庫的核心理論與實務,三版,黃三益著,2007
- Software Engineering for Information Systems, Donald C. McDermid, 1990